My Clojure Vacation
So: I had a little break from work. I used it to take a break from my professional weapon of choice for many years: Android.
Why did I do it? Honestly, I didn't know at the time. The heart of a decision is rarely a reason; usually it's a feeling. I had some negative feelings. I don't have a good reason to share them, so I'll keep them to myself.
My vacation, though, brought up a lot of fun new things. So at the risk of writing one of those weird gushy posts about a hopelessly niche thing, I'll go ahead and share them.
Small server; team of one
In my vacation I built something in Clojure: a small web server that dynamically serves content from a hacky little data backend I wrote. It was a great experience that changed how I viewed the way I'd been writing code for all these years.
So what made it so different?
Programming for fun
The idea of programming in my spare time simply to sharpen the professional saw never spoke to me, and it still doesn't. Free time is free time, and fun is fun: don't mix the two. Writing code to further my professional career is just more work.
That's not how I started programming, though. I wrote my first code to have fun: I was bored in math class. Why listen to the teacher explain how last night's assignments were done when I can build something on my TI-83 instead?
I was only trying to kill time. But I wasn't programming to make someone else happy, or to be useful. Using something other than Android helped set my efforts at a considerable distance from those motivations.
Programming as a creative impulse
Even then, sitting down as a lark to write some code wouldn't have lasted long. What's the point? And sitting down seeking to accomplish some project as a standard of performance I wanted to meet or a feather in my cap was excruciating. I have a horrible ego, and can't go down that path without being crippled by self-criticism.
But I already felt crippled. Without even trying, I was constantly doing whatever I could to get out of my own head. I wanted to scape all of that: escape from the television, from YouTube, from video games, Facebook, Twitter, Slack and all the attention loops that lay scattered about my life like anti-personnel mines.
So I cut them out.
Where did that leave me? Alone in an empty field, that's where. And that was where the creative impulse put up shoots.
I loved it. I felt invigorated. I don't know that Clojure has anything to do with that, but when you're in that mood you just have to roll with what works.
Immediacy!
Programming in Clojure was immediate! Everything that I wanted to do could be accomplished right there, instantly.
People use the acronym "REPL" (short for Read-Eval-Print-Loop) to refer to these immediate environments. I had fired up command line REPL interpreters for Python, Ruby, and so on, but I didn't get it.
But I worked through Clojure For the Brave and True, I started using Emacs, and I followed instructions from other people about what to do. When I got up to speed, I found that from within my editor I could use the language and runtime to write code and investigate its behavior within the running system.
I could tinker! Soon my runtime became a running web server with non-zero overhead and startup time. I found that I could jack straight in to the server and patch it live with new and altered code, never needing to wait to recompile and redeploy.
And as maligned as the parens are in Lisps like Clojure, their unwavering structure gave the same immediacy to evaluating and observing each piece of my program. Bind the right names to the right values, and any piece of any function can be run on its own.
A different model of mutability
Clojure is not a side-effect-free world. Even writing purely functional code, learning Clojure effectively requires one to understand the workings of a mutable runtime. As a Clojure application is brought into a running state, the useful mental model is that every single function definition mutates a namespace's bindings to a new configuration.
Once the app is up and running, the steady state is indeed by and large immutable. All the best tools in the toolbox work with immutable values, and additional effort has to be expended to make a piece of the program work in a stateful manner. Mutability is reserved for those parts of the system that demand it (like the network, services that must be started and stopped, or library dependences that have stateful APIs).
The reliance on mutability to do the work of wiring up the system makes it possible to tinker with the system as it's running. This is a drawback to lexical bindings: if you lexically bind a large piece of machinery and hand it off, it's no longer possible to tinker with it in this way. You have to build a whole new large piece of machinery and hand that off. In my case, I ended up needing to reboot the web server to change the routing table.
At runtime, tinkering can be a formidable complication, particularly if the program tinkers with itself. But when you've built something with some inertia, that can't be rebuilt and rerun as a whole at small cost — oh, tinkering is heaven. It is a powerful way to get shit done.
Primacy of the data itself
I had watched a few Rich Hickey talks before I got started on this project, so I had seen him use the phrase "value-oriented programming." So when I first started out, I diagrammed my idea of where data would flow through the system, and gave a name to the kinds of values that I would have. "Hmm," I thought, "how can I use Clojure to define a type for this class of value?"
That's what I'd do in Java, after all: I'd define a class called RemotePost with the fields I want, and use that as my immutable value object.
Clojure has a tool called the Record that seems to match this concept. After some time spent with it, though, I realized that I was fighting the APIs.
See, I wanted to create a RemotePost type. By and large, though, Clojure-y abstractions frequently don't care what type of data is passed in. They usually care about the shape of that data, what sort of values may be accessed with it.
Here's what I mean by the "shape" of the data. Imagine I defined a RemotePost type in Kotlin:
data class RemotePost(
val title: String,
val timestampMs: Long)
This is generally how I'd pass data around in Java or Kotlin: as instances of a concrete type with properties.
In Clojure, I would instead create a map with keys for the keywords :title, :timestamp-ms, and so on, mapping them to appropriate values:
{:title "My Clojure Vacation"
:timestamp-ms 1589777804391}
For processes that consume this data, the only important thing about it is that it has a string value at :title and a millisecond timestamp value at :timestamp-ms. This is the equivalent to a RemotePost: a piece of data with the right shape in these aspects. (And yes, Clojure calls the :title construct a keyword. Don't ask me, I just work here.)
I found this disconcerting. I did some work early in my career with Python where I didn't rely on strict typing; the resulting mess was bad enough that I have cast wards against it for the rest of my life. But this is indeed the best practice in Clojure.
Structure-oriented data discipline
There is a spirit of discipline about it all, though, if an unfamiliar one. The spec framework provides a common toolset for establishing the shape of data objects, and a lot can be learned about Clojure design sensibilities from understanding it.
spec has a way of working with keywords that surprised me. In spec, if you want to ensure that the keyword :timestamp-ms is bound to a valid millisecond timestamp, you bind a data spec to the keyword. Here is a construct that uses the s/and function to create a data spec and the s/def macro to bind it to the ::timestamp-ms keyword:
(s/def ::timestamp-ms
(s/and int?
can-be-converted-to-instant?
is-plausibly-within-bills-lifespan?))
(The extra : on ::timestamp-ms means that this is a keyword in a local namespace — an important precaution, since binding to a global namespace would result in all kinds of unfortunate clobbering.)
The names ending in ? all refer to predicates: functions that take in a value and yield either true or false. So this spec says that a valid ::timestamp-ms is described by the given three predicate functions, all of which will return true for a valid timestamp.
Within this namespace, the name ::timestamp-ms always refers to the same kind of data wherever it is seen. How interesting is that? It's not what I expected, but now that I've seen it I think it would be confusing to treat names differently in my own codebase.
So let's say I want to describe a data structure that has a timestamp in it. I can define that description by using the function s/keys, which builds a data spec that matches a map with particular keys. Then I use def to assign that data spec to a regular old variable:
(def timestamped-map
"A map with a timestamp in it."
(s/keys :req [::timestamp-ms])
So if I mapped a value to the ::timestamp-ms key:
{::timestamp-ms (System/currentTimeMillis)}
I could use timestamped-map to validate it:
> (s/valid? timestamped-map
{::timestamp-ms
(System/currentTimeMillis)})
true
> (s/valid? timestamped-map {:timestamp-ms 15})
false
And because I used spec's tools for defining my data spec, I can also get some simple error reporting:
> (s/explain timestamped-map {:timestamp-ms 15})
15 - failed:
is-plausibly-within-bills-lifespan?
in: [::timestamp-ms] at: [::timestamp-ms]
spec: :gascan.post-spec/timestamp-ms
This is a simplified view of spec. Since spec describes the shape of data, it can be made to serve in a wide variety of other scenarios, like generating test data.
Yet in some other ways, this is still less than what a typical type system does. There's no strictness provided: there's no way to know exactly what sort of object came into your system. There's no way to tell from an instance where it was defined, as you can in Java.
In return, though, with even this small scenario you get a validatable guardrail that maintains flexibility and dynamicism in the system, and retains the ability to create value objects with the standard REPL tools that can be consumed anywhere, without needing to refer to a particular classpath and a particular implementation. As a result, most of the things that drive the app live in an interoperable lingua franca.
This is a serious trade-off. As a hobbyist I love the flexibility, but as a professional the idea of being unable to find where my data was constructed in an unfamiliar codebase is a little terrifying. The mechanism of namespace keys would fix this to an extent, but they are not in common usage.
Distinction between data and functions
From a design perspective, I appreciated that data and functions lived separate lives. There were certain entities that did live an object-y life of keeping track of a changing bit of state, but this was the exception rather than the rule.
This was at its best in a design context. In the past few years, the lack of expressivity in objects had started to wear thin on me. As a design tool, it no longer felt like it was revealing edges. All the edges were elective: a single responsibility in one context would be an overgrown monstrosity in another.
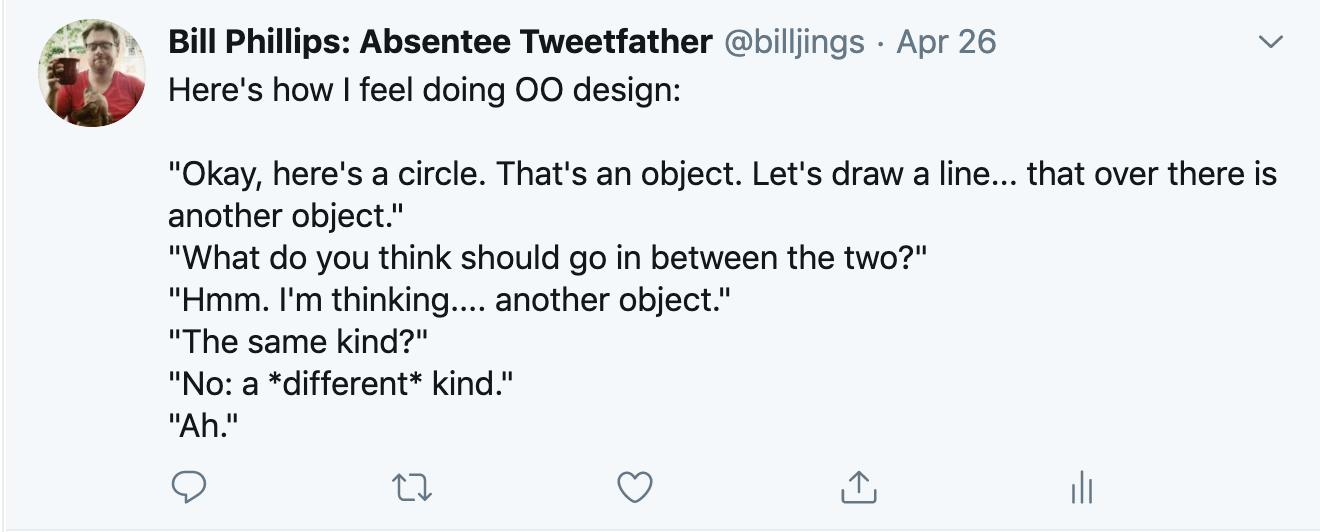
I was unable to express different roles in any way other than to put different words on things, and I was tired of it. Drawing a distinction between functions and data and denying capabilities to one or the other makes a lot of sense! This restriction forces a lot of things to be teased out that would otherwise stay put.
The vacation is over
I recently started working at Cash, so my vacation is at an end. I'm once again working on a big client, with big build times. Sigh.
There are some nice things: we have a firmer line between processes and data than any other codebase I've worked on. But is it possible to tinker with it?
I've got lots of real work to do now. But maybe...
references
Thanks to Nick Black and Joe Lafiosca for their feedback. One of them also sent me a quote of a wonderful passage from Infinite Jest, for which I am also grateful.